浅谈RabbitMQ的高可用:集群、故障重连与多机房部署
RabbitMQ 是靠集群实现高可用的,不过集群并不能完整的提供高可用服务,还需要应用程序侧(即生产者、消费者)实现与集群故障重连的逻辑。对于更高的可用性,可以使用 RabbitMQ 的插件来实现(通过部署多集群,消息复制的方式来保证)。
集群
RabbitMQ 的集群的设计目标有两个:一是允许消费者和生产者在 RabbitMQ 节点崩溃的情况下继续运行,二是通过添加更多的节点来线性扩展消息通信吞吐量。RabbitMQ 是通过 Erlang 提供的开放电信平台[^1] 分布式通信框架来巧妙的满足以上两个需求的。
集群架构
队列
每个队列在 RabbitMQ 中都有独立的进程。RabbitMQ 中的队列在单节点和集群模式下有不同的数据分布策略。在单节点模式中,所有关于队列的信息(元数据、状态和内容)都保存在该节点上。但如果在集群模式下创建的队列,集群只会在单个节点[^2]而不是所有节点上创建完整的队列信息(元数据、状态、内容)。结果是只有队列的所有者节点(owner node)知道队列的所有信息,所有其他非所有者节点只知道队列的元数据和指向所有者队列的指针[^3]。
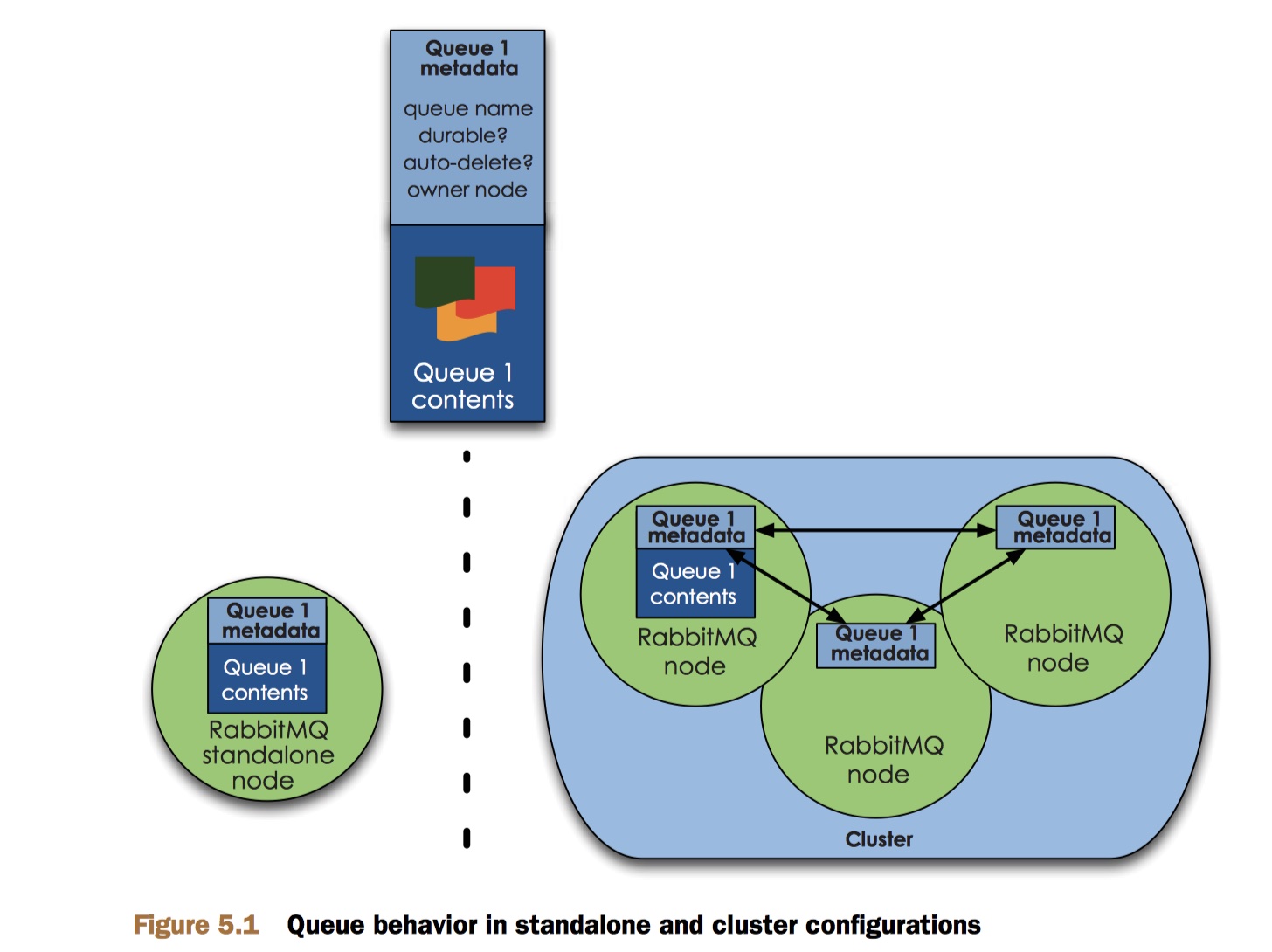
此时,如果某个节点挂了,该节点的队列和关联的绑定都消失了,队列的消费者也不能再收到该队列的消息,而且任何匹配该队列的新消息也都丢失了。看起来糟糕透了,但别担心,我们可以让消费者重新连接到集群并重新创建队列(仅适用于队列最开始没有被标记为可持久化时才行),如果重新创建的队列被标记成持久化了,重新创建会得到一个 404_NOT_FOUND 错误。这样确保了当失败节点恢复后加入集群,该节点上的队列消息不会丢失。想要该指定队列重回集群的唯一方法是将该队列所在的节点故障恢复过来。
为什么默认情况下 RabbitMQ 不将队列内容和状态复制到所有节点呢?RabbitMQ 社区给出两个原因:存储空间[^4]、性能[^5]。
小结:RabbitMQ 不能对故障队列自动恢复
分布式交换器
不同于队列拥有自己的进程,交换器在 RabbitMQ 中仅仅是一个名称和一个队列的绑定列表(数据量很小,不过是一个根据消息绑定规则查询对应队列进程地址的查询表)。当创建一个新的交换器时,RabbitMQ 会将其在整个集群复制。当某个节点挂了,由于有别的节点上的交换器冗余备份,因此是高可用的。
小结:RabbitMQ 会在每个节点都保存一份交换器数据,但高可用性需要结合事务或者生产者 ack 机制来保证
是内存节点还是磁盘节点
每个 RabbitMQ 的节点,不管是单节点模式还是集群模式,要么是内存节点[^8](RAM node),要么是磁盘节点[^9](Disk node)。当在集群中声明队列、交换器或者绑定的时候,这些操作会直到所有集群节点都成功提交元数据变更后才返回。RabbitMQ 要求集群中至少有一个节点是磁盘节点[^10],但通常建议设置两个以上。
小结:至少设置两个节点为磁盘节点,来保证一系列创建操作是高可用的
镜像队列和保留消息
在 RabbitMQ 2.6 之后,Rabbit 团队给我们带来了双活冗余选项:镜像队列[^11] 。
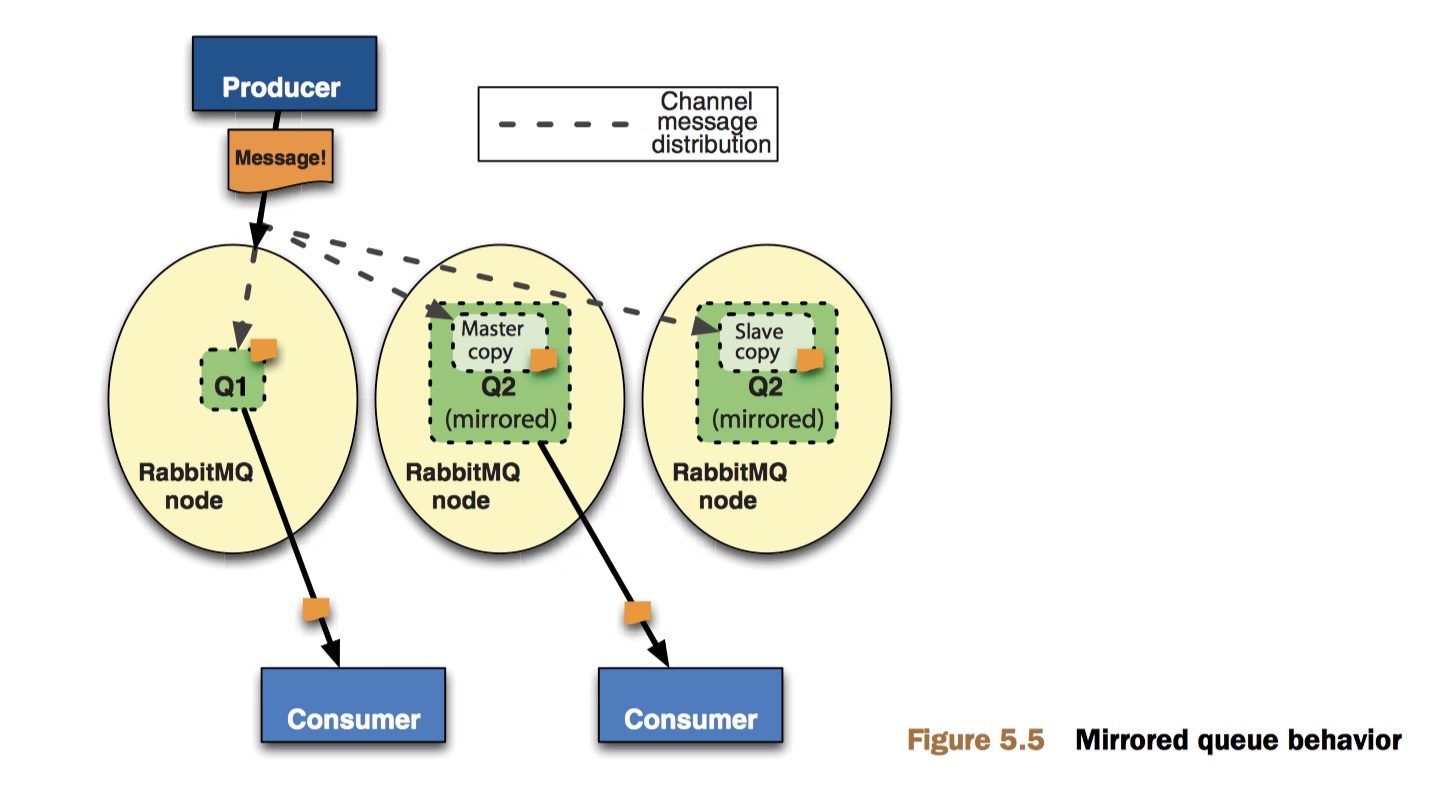
小结:镜像队列基于主从架构保证了队列级别的高可用
从故障中恢复
当节点发生故障时,应用程序要知道如何重连到集群。在 RabbitMQ 中,有多种重连策略,我们讨论的是使用负载均衡来处理节点的选择。通过使用负载均衡,不仅可以减少应用程序处理节点故障代码的复杂性,又能确保在急群中连接的平均分布。
为 RabbitMQ 做负载均衡
当为 RabbitMQ 添加负载均衡器时,集群节点就作为负载均衡器背后的服务器,而你的生产者和消费者就是客户端了。RabbitMQ 需要四层负载均衡器,无论硬件还是软件都可以。目前的生产实践中,一般通过 HAProxy[^12] 作为 RabbitMQ 集群的负载均衡器。
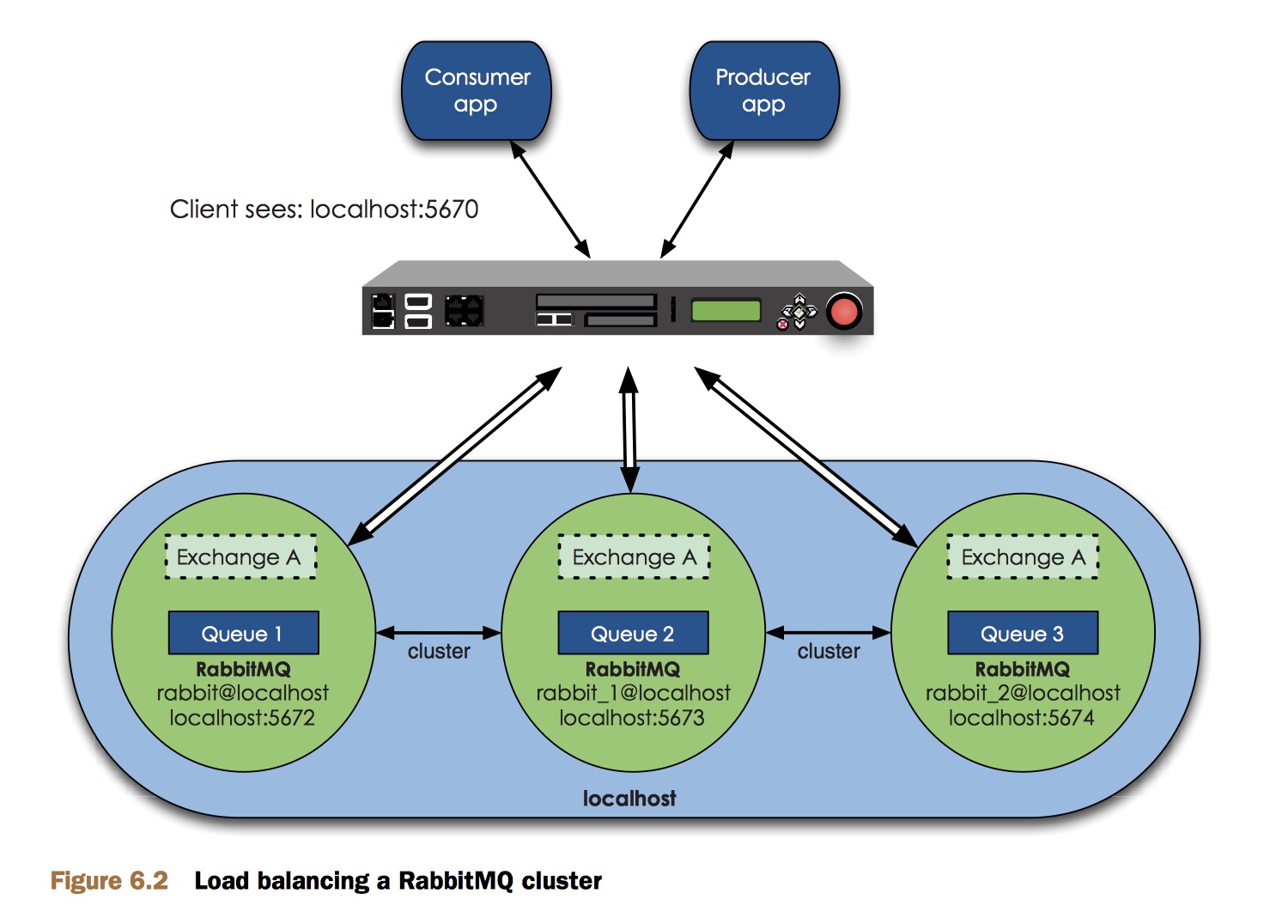
当节点故障时,我们只需要在应用里重新连接集群,并重新创建队列、交换器、绑定进行消费即可。
网络分区问题(脑裂)
默认情况下,RabbitMQ 不会自动处理网络分区[^13],即使网络恢复了,也同样。我们需要配置cluster_partition_handling参数来使集群自动处理。不过,实际场景下,我们需要对分区问题进行监控[^14],及时发现才能处理得当。
多机房部署
写到这里笔者发现以目前的业务场景,距离多机房还尚远,笔者碰到了此需求再写吧~
最后附上一个小规模 RabbitMQ 集群的参考部署架构

参考资料
脚注
[^1]: OTP(Open Telecom Paltform)
[^2]: 与客户端连接的那个节点负责创建队列
[^3]: 可以理解成所有者节点的 IP 地址
[^4]: 社区认为如果每个集群节点都拥有所有队列的完整拷贝,那么新增节点也无法给你带来更多存储空间。(在 RabbitMQ 诞生的年代,数据分片、复制这些理念在消息队列领域很少应用,RabbitMQ 的设计理念在当时还是很先进的。另一方面,简单的架构往往更加健壮,比如更易恢复)
[^5]: 消息的发布需要将消息复制到每一个集群节点。对于持久化消息来说,每一条消息都会触发磁盘活动。每次新增节点,网络和磁盘负载都会增加,最终只能保持集群性能的平稳(甚至更糟)(此处让笔者体会到了架构设计对系统的深远影响,当新的挑战来临时调头难,除非推倒重做)
[^6]: 此处与 RabbitMQ 的消息路由机制(当你将消息发布到交换机时,实际上是由你所连接到的信道将消息上的路由键同交换器的绑定列表进行比较,然后路由消息)有关,如果碰巧消息发布到信道上,在路由完成之前节点发生故障的话,默认情况下就有丢失消息的风险了。解决方法是使用 AMQP 事务,在消息路由到队列之前它会一直阻塞;或者使用发送方确(publisher confirm)模式来记录连接中断时尚未被确认的消息(这种 ack 机制在消息队列很常见,不仅可以处理节点故障问题,也可以对抗网络抖动造成的消息丢失)。
[^8]: 内存节点将所有的队列、交换器、绑定 、用户、权限 和 vhost 的元数据定义都仅存储在内存中。
[^9]: 磁盘节点则将元数据存储在磁盘中。(注意,在单节点模式下,仅允许磁盘节点,否则一重启 RabbitMQ,啥都没有了)
[^10]: 如果集群只有一个磁盘节点,刚好挂了,那么集群只能路由消息不能进行如下操作了: 创建队列、创建交换器、创建绑定、添加用户、更改权限、添加 或删除集群节点
[^11]: 像普通节点那样,镜像队列的主拷贝仅存在于一个节点(主队列,master)上,但与普通队列不同的是,镜像节点在集群中的其他节点上拥有从队列(slave)拷贝。一旦主队列不可用,最老的从队列将被选举为新的主队列。
[^12]: HAProxy 是一款开源免费的四层/七层负载均衡器,据我所知,Stack Overflow 也在使用它。
[^13]: 网络分区是在使用 RabbitMQ 时所不得不面对的一个问题,网络分区的发生可能会引起消息丢失或者服务不可用等。可以简单地通过重启的方式或者配置自动化处理的方式来处理这个问题。更多请见 http://next.rabbitmq.com/partitions.html
[^14]: 对网络分区监控一般通过日志或者 HTTP API 的方式进行,具体请见 http://next.rabbitmq.com/partitions.html#detecting
- Title: 浅谈RabbitMQ的高可用:集群、故障重连与多机房部署
- Author: 侯乾
- Created at : 2017-05-13 19:12:11
- Updated at : 2017-05-13 19:12:11
- Link: http://houqian.github.io/2017/05/13/浅谈RabbitMQ的高可用:集群、故障重连与多机房部署/
- License: This work is licensed under CC BY-NC-SA 4.0.